
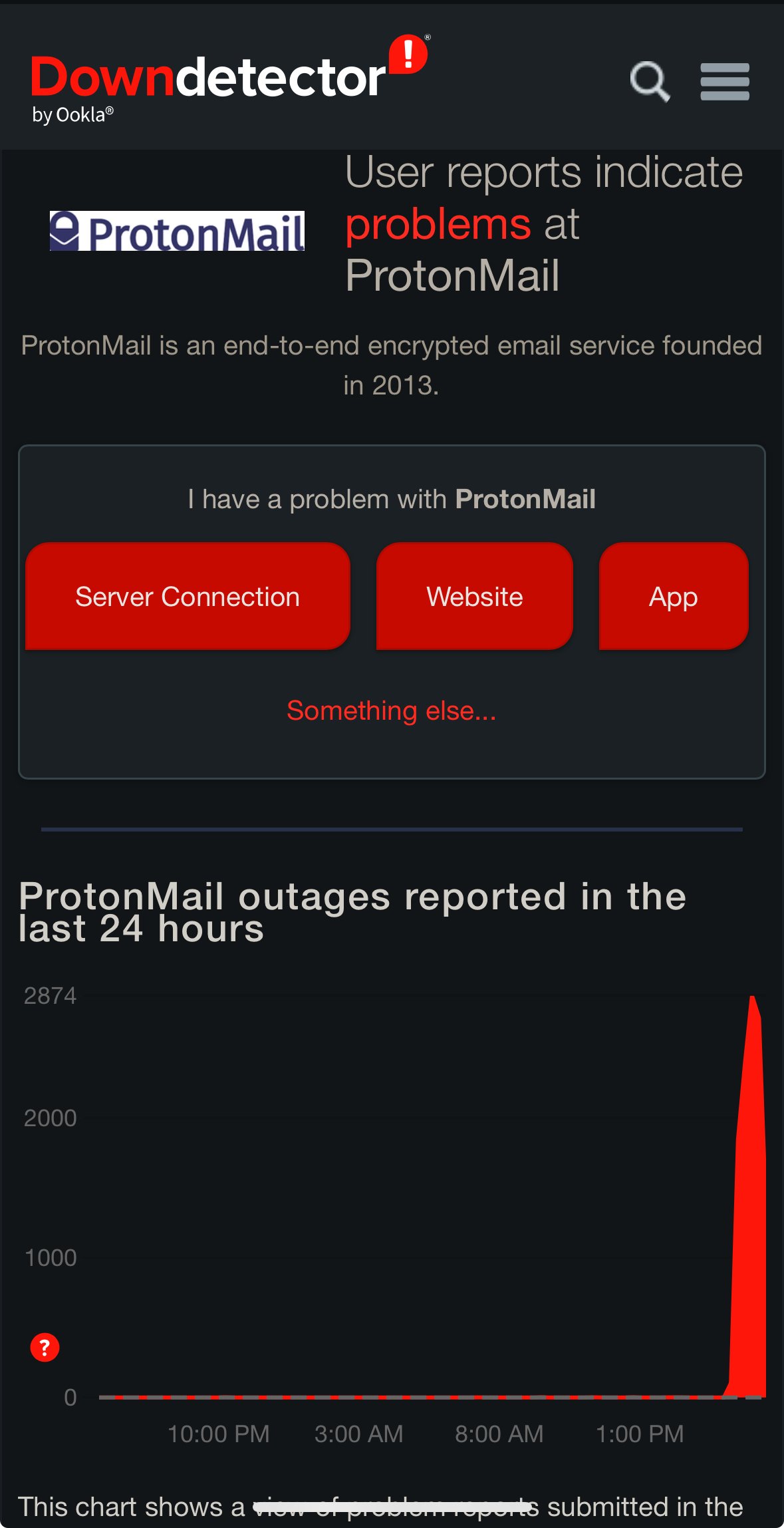
Been down for a couple hours for me.
You must log in or register to comment.
Same. Which is whatever, I’m more annoyed they haven’t updated their status page.
Yeah, incredibly frustrating.
The only acknowledgement is from a volunteer mod on reddit that said an hour ago that “the team is aware and the status page will be updated shortly”.The fact I had to dig around to find that is really not a pleasing experience.
Why does a status page need to be updated manually?
Servers could still be up and responding to pings, yet backend databases could be down.
Or it could be a caching problem with the status service.
It’s bad ways of handling your status page but it happens.
It’s also a business decision. Many times companies will massage their verbiage and have a plan in place before they even change the status to “investigating” simply to appease when they have SLAs. It’s stupid, but that’s often the reason.
There’s also a insurmountable amount of potential issues to cover, not worth the automation
It depends on the services, but in the end it’s pretty easy to spoof handshake packets to see if a service on a server is still running.
nmap is a great example.
I meant on the logic side of things
Maybe somehow the problem was triggered in a way that the status page didn’t automatically detect it (for example, mine still works)? I’m really grasping at straws with that one. If it isn’t automatic, it categorically needs to be; if it is automatic but missed what’s apparently a major outage, then it needs to be fixed.
Yeah, I’m used to company status pages being the last to know.
Their status page has an update on what happened.
Service instability due to network incident Resolved - Due to an undocumented change in an operating system update shipped by one of our network equipment vendors, network devices in our Frankfurt datacenter experienced an unexpected partial failure.
This incident impacted primarily Proton Mail, with approximately 50% of users who were routed to the impacted datacenter experiencing intermittent downtime for approximately 1 hour. Due to redundant systems, no data or emails were lost, but some email delivery may have been delayed.
Incident report: Because the failure was partial, it was not sufficient to trigger a failover. Due to the unique circumstances surrounding this failure, a significant amount of confusion led to a longer than usual delay before the infrastructure engineers on shift made the call to failover to an alternative site.
That restored services, with approximately 30 minutes of lingering low-level instability while load was rebalanced. Investigation that took place in parallel uncovered the undocumented operating system change in the network device update that was rolled out earlier this month. Impacted network devices were updated, and the Frankfurt datacenter brought back into production with no user impact. Proton routinely conducts testing before rolling out software patches to our network equipment and rolls them out gradually.
Unfortunately, this problematic undocumented change was not discovered because it only created issues under specific load conditions (indeed, the new software had been running for weeks without issues).
We apologize for the longer than usual incident response time. In the coming days, we will be analyzing our response to this incident to reduce future reaction times.
FYI my proton mail mail works.
Mine too
It must be regional. It’s been fine for me all day.
The iPhone app kept working for me, but the proton mail website was inaccessible for about 2 hours.
No problems with mine all day.
It had signed me out of the Proton Mail App on Android, first time that’s ever occurred, not sure it’s related though?
Me when I test something in production







{kind=link}